
News can be good or bad, but it is seldom neutral. I was interested how certain news agencies reported on a variety of topics, are they positive, neutral or negative?
After skimming through some interesting datasets and articles on the internet, I found some insights. But first....
What is sentiment analysis?
Sentiment analysis gives an idea of the sentiment behind a given piece of text, it combines machine learning and natural language processing (NLP). After the program crunches data and categorises words it gives an approximation whether the sentiment behind a piece of text is positive, negative, or neutral.
So that's it, a computer measurement of a body of text as positive 👍, negative 👎 or neutral 😐.

Sentiment Analysis is a powerful technique in artificial intelligence that is important in business applications, eg analysing customer feedback collected from Twitter/Facebook and analysing those text snippets to understand the attitude (handy for marketing and customer service).
How is sentiment analysis performed?
First you need a data set, a large data set, over 1,000 articles or 10,000 words. Then you put that data set into a series of programs and processes that build relationships between the words. The way the relationship(s) between words is constructed depends on the method that the programmers used to identify the relationship, several processing models include BERT, GPT3 and Word2vec.
These programs work principally by creating word embeddings that one word has with another - for example, does this word "king" have a strong relationship with "queen". Here is a word embedding diagram prepared by @JayAlammar on his explanation piece The Illustrated Word2vec:
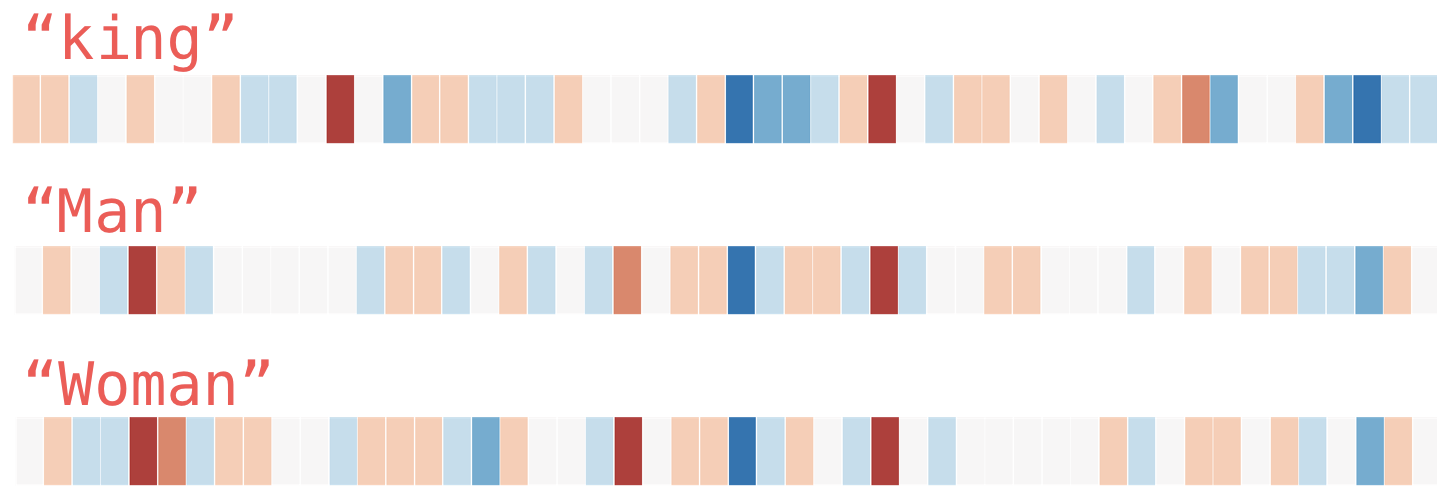
These word embedding models are used in a wide variety of text based applications: predicitive text, google search auto-complete, recommendation engines, making sense of sequential data in commercial and sentiment analysis. Companies like Airbnb, Alibaba, Spotify, and Anghami have all benefitted from the world of NLP.
To find out more take a read of these two helpful articles, I'll move now onto showing some cool findings from research papers:
Looking at Some Sentiment Analysis Reports
I found two sources that got close to the data I was looking for:
- Sentiment Analysis of A Million News Headlines - Nov 2017
- Large-Scale Sentiment Analysis for News and Blogs - 2007
In 'Large Scale Sentiment Analysis for News & Blogs' they built a relationship between words in a unique way. They used the distance between concepts to generate the spectrum or steps.
Paths which alternate between positive and negative terms are likely spurious.

I have charted that data from 2007 below to give you an idea of the sentiments across categories. If we look at the hand-curated data, then subtract the negative score from the positive we are left with the balance, the results are:
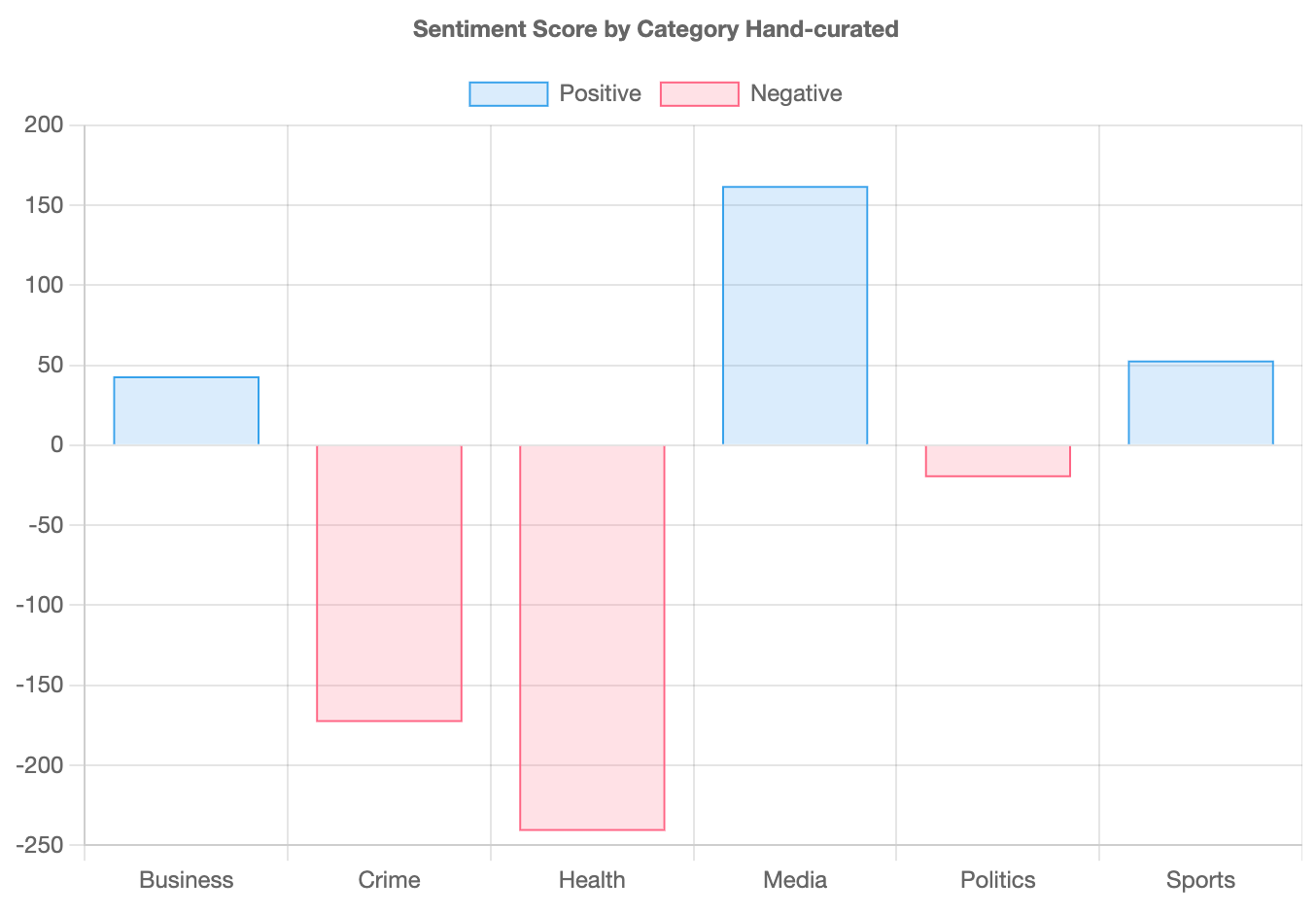
The main takeaway from the chart above is that the topic of health and crime are associated with negative sentiment of the six chosen topics. Possibly, this presents a unique challenge or opportunity for marketers in the health space.
Australian News Headlines
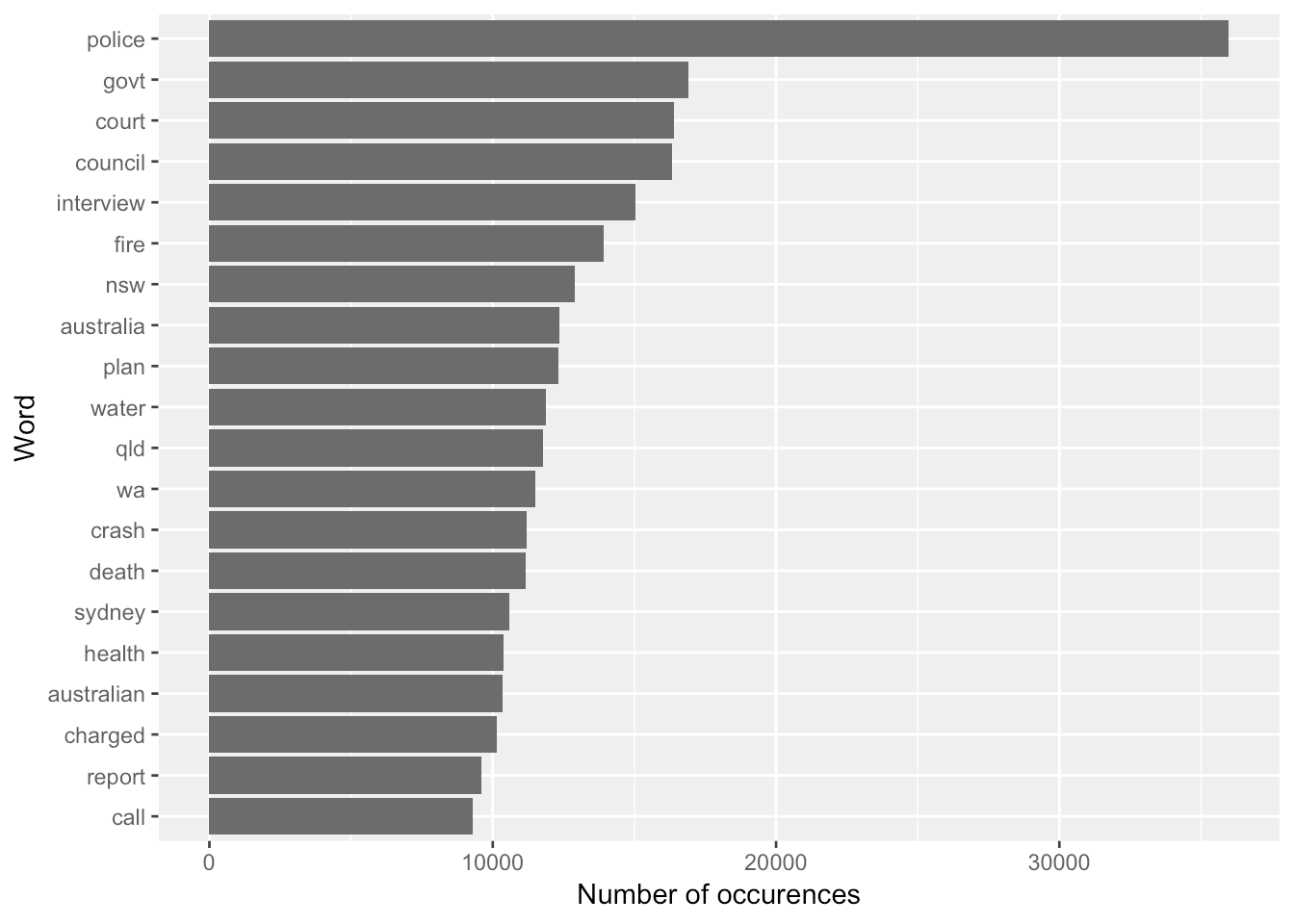
Akmal Abdul Rashid a Data Scientist at The Center of Applied Data Science provided this awesome summary of news headlines published over a period of 14 years from 2003 to 2017 from Australian news source ABC(Australian Broadcasting Group). This data set was provided as open source on kaggle.com but it is his analysis that is thought provoking. I am very grateful for this research 🙌.
According to Akmal, here are the most frequent words and sentiments used in the ABC news headlines since 2003:
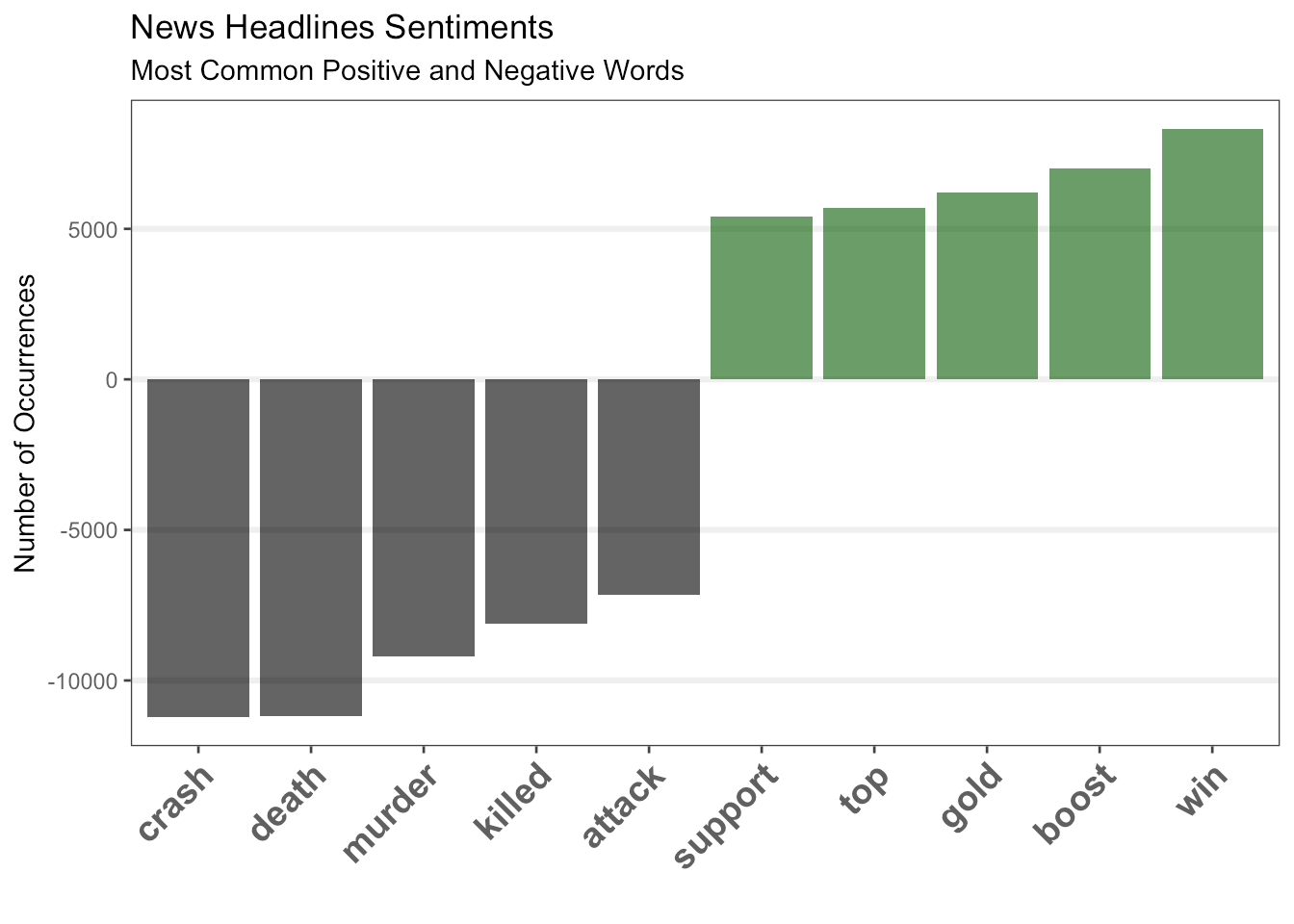
This next word cloud is very interesting. These are the most popular sentiment words. I wonder what the most commonly used headline words are for other countries?

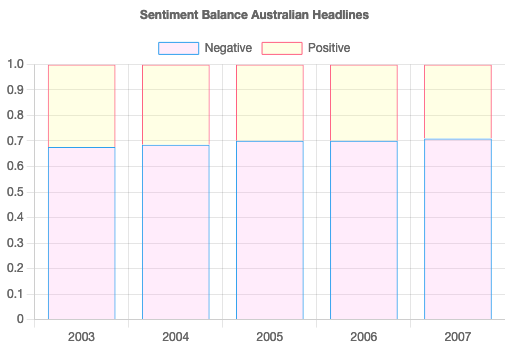
I have charted some of the other data in the report to reveal the balance of negative/positive sentiment in the headlines from 2003 to 2007. It shows that in general the headlines are negative 7 out of 10 times, however just to reiterate, the neutral sentiment headline words were filtered from the data set.
The proportion of negative sentiment words has been consistently much higher than proportion of positive sentiment words since 2003.
Source: https://akmalrashid.com/post/2017/11/26/sentiment-analysis-of-a-million-news-headlines/
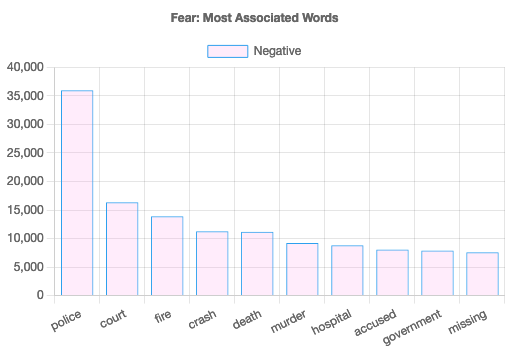
Fear leads the way
Akmal investigated a library called NRC to conduct analysis on emotion terms: Anger, Anticipation, Disgust, Fear, Joy, Sadness, Surprise, and Trust (there are many more words available).
Fear has highest percentage in the distribution. Next, we can see how the sentiment emotions of headlines change over time by creating bump chart that plots different sentiment groups.
Source: https://akmalrashid.com/post/2017/11/26/sentiment-analysis-of-a-million-news-headlines/

Filtering for a specific word: "Fear"
The next set of data use with the NRC model is interesting, it reveals what the most used words are associated with fear. This type of filtered analysis is beneficial as a temperature gauge of brand/topic/issue and can be used across many industry verticals to provide insight to strategy and planning.
How might the newspapers report on certain issues? Famous people? Ethnicities? Locations? Politicians? Contentious issues? I would suggest that this type of research is the first step of any marketing & communications body of work as well as understanding if your story fits with a certain publication and it's audience.
Beware of the variances in models
The paper by Akmal also briefly shows the weighting of the models, that is a comparison of the same words sets on the NRC lexicon, Bing lexicon and AFINN lexicon.
We can see that AFINN and Bing lexicon sentiment across the years have been negative, there’s really no positive sentiment at all! But we can see in the latest index the negative score is really small, is the trend changing? we need more data to confirm that. Generally, across all lexicon, the sentiment of the headlines has all been negative.
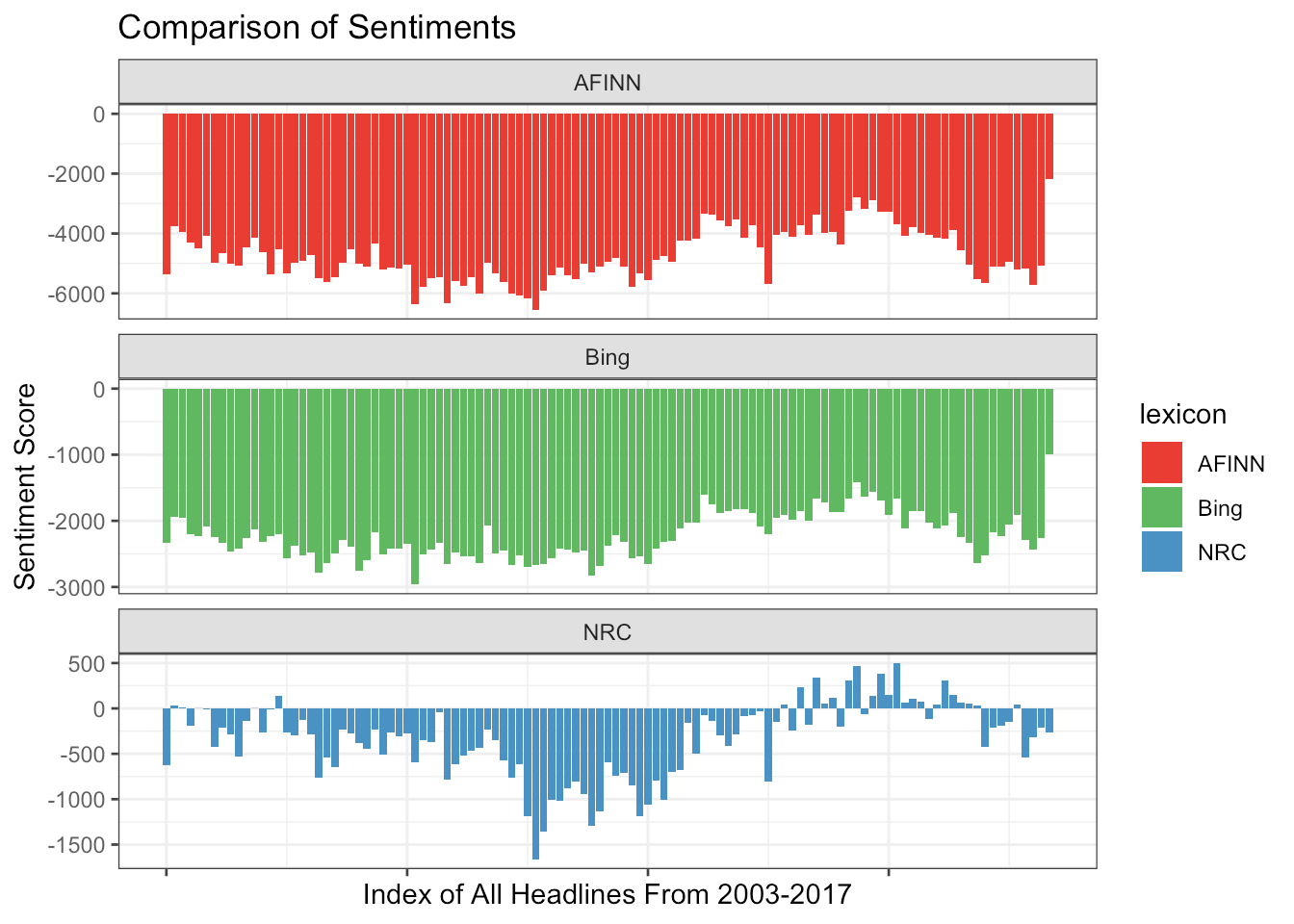
Beware of the words not understood by the model
NRC lexicon, Bing lexicon and AFINN lexicon failed to categorise the following words
- Bing: 4,652,959
- NRC: 3,982,132
- AFINN: 4,532,575
Summary
So how have certain news agencies reported on a variety of topics? Are they positive, neutral or negative? After skimming through some interesting data sets and articles on the internet, we can see from the analysis that negative sentiment has been dominating both the very large scale data set and the media headlines in Australia.
In the large data set it is mostly negative reporting on crime and health but positive on business, media & sports. In Australia fear was the dominating theme and associated most with the following terms police, court, fire, crime , crash, death, murder, hospital and others. Headlines in Australia are mostly negative 7 out of 10 times.
It is important to note that these models and data set packages are not the only sources for sentiment analysis. It is possible for others to create their own lexicons through crowd-sourcing and science and research projects (i.e, Te Hiku Media or Amazon Mechanical-Turk). It is also possible for companies to use their data from years of dealing with customers, employees and feedback to inform their lexicon library.
My next side-line project is to develop and analyse datasets for the Pacific region. With articles and headlines from media agencies, reports from government oranisations (such as justice and social organisations) to reveal more insights into who we are, what we talk about and how we reflect on this changing world. Kia ora 😀.



